

Consistency and Deduplication
Consistency
One of the key things you need in any BI tool is consistency. The different charts and tables you display on your business dashboards need to always tell the same story. The last thing we want is for one report to say that a key metric has been going up, but another report to show the same metric going down.
Deduplication
Consistency and deduplication go hand in hand. When you start a new report that is closely related to an existing report, you’ll normally want to re-use a lot of the work that went into the last one.
Copy-Paste
I’ve seen people simply copy and paste the body of one report and use it to start the next one. This is great for when you’re doing experimental, throw-away work, but absolutely terrible if you want your reports to be easy to maintain in the long run.
The big problem with copy and paste is that you’ll inevitably need to make updates or enhancements to the code that you copied, and when that happens, you’ll have to track down all the places it was copied to and update them all together.
Shared Artifact
A much better approach than the copy-paste is to create some kind of shared artifact with clear semantics. Normally, this consists of some kind of shared data table. You create the table once, and then re-use the same table in several reports that need to use that data.

Once you start sharing tables this way, a lot of the work in getting your reports to look good is no longer part of the reports themselves, but part of the shared tables that they use. That’s a good practice because it keeps concerns separate: the “data concern” work stays in the tables, and the “visualization concern” work goes into the reports.
Deeply Nested Sharing
Naturally, you’re going to want to have your tables share common logic with each other, leading to more deeply nested dependencies between artifacts.

In the diagram above, Shared_Table_X is used by two reports and by two other shared tables. Again, this is another good practice, especially if you want future enhancements to the logic in Shared_Table_X to influence everything else down the line.
Introducing Data Pipelines
At the end of the day, there’s not much of a difference between the kind of shared tables described above and a full-fledged “data pipeline”. Often, a company will use a separate software product for each, but the two products will have a lot of overlap.
Data Pipeline
A “data pipeline” is a sequence of computational jobs that run on a schedule and produce new data artifacts from old ones. Sometimes they’re called ETL or “Transformation” pipelines. A few popular examples are Apache Spark, Luigi, Databricks and DBT.
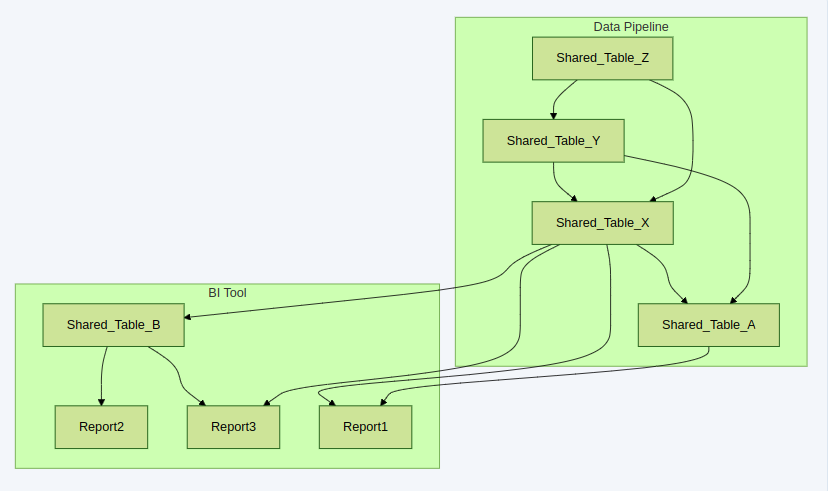
Companies that use both a BI tool and a Data Pipeline tool wind up with data artifacts that live in either one or the other:

Before creating a shared data table, employees at the company always need to decide whether to put it in the data pipeline, or the BI tool. Often, that choice is determined by role: The data science and software engineering organizations use the data pipeline, and operations people or business analysts use the BI tool.
Problems with the split BI Tool + Data Pipeline Approach
Architectures like the one above turn out to be extremely common, especially inside larger organizations, but they inevitably run into a number of problems:
Complex Debugging
This architecture can make debugging reporting problems much more complex because there are two separate systems involved. Maybe the person investigating a BI tool report isn’t familiar with the data pipeline and has to pass off the investigation to someone else, or worse yet, they try to patch the fix from the data pipeline by making changes to the shared tables in their BI tool.
Duplication of Work
Inevitably, people will wind up solving the same problems in both the data pipeline and the BI tool, or people on the business/operations side will start solving problems that the data science team wanted to handle instead. Problems like this occur naturally with whatever tool you use, but when things are split between two systems, it makes the whole situation a lot worse.
Confused Scheduling
The job of a data pipeline scheduler is to make sure all the data artifacts are recomputed at the right times. When some artifacts are in one scheduler and some in other, the whole thing turns into a big mess.
Difficult Previews
Any BI tool can let you preview changes you might want to make before sharing them with the rest of your team, but previewing changes is much harder when you want to see how a change to a Data Pipeline affects reports in your BI tool.
For all the reasons above, it’s advantageous to have a single tool that does all your data transformations, starting from raw input data, leading all the way to running the BI experience for end users:

Getting the Most out of an Agentic AI Assistant
Naturally, everyone is excited to incorporate an AI assistant into their BI workflow and use it to automate away tedious work and boost efficiency. To get the most out of an AI assistant, however, you’re going to need a few key things:
- Give the AI assistant as much context as possible
- Let the AI assistant make bold, sweeping changes across your data stack, but keep them in an isolated preview so that people can review the assistant’s work to check for mistakes, errors, and hallucinations.
Now ask yourself, do you really want two distinct AI assistant agents, one for the BI tool and one for the Data Pipeline? What happens when you ask the BI tool agent a question that depends on information in the data pipeline? Will it get lost and complain that the problem is with the input data? Do you want the two AI assistants to talk to each other to collaborate on solving problems? And which company is responsible for giving you a good experience with the AI assistant?
With a split BI tool + Data Pipeline architecture, no one assistant will have enough context to understand problems that come up across both domains, and no one assistant will be able to make tandem changes to both systems at once. In effect, all the problems from splitting your data stack between several different layers of tools are going to be compounded in the age of agentic AI assistants.
Wrap Up
I touched above on how every BI tool is going to need to incorporate some of the functions of a data pipeline, explained some of the problems I’ve seen and heard about when companies split the Data Pipeline stage out from the BI tool, and gave reasons why a combined BI Tool + Data Pipeline architecture will become even more advantageous as we rely more on AI assistants to help us analyze our data.
These considerations also motivate the design of Quodor Data's bi tool, which is from the ground up structured as a combined BI tool + Data Pipeline with an embedded AI agent, capable of assisting with both use cases. I hope you take the time to check it out, and if you’re interested in being an early user, please get in touch!

